商业广告QQ
896000434
896000434
该研究以:PFMBench: Protein Foundation Model Benchmark为题,于近日发表在了预印本平台 ArXiv 上。
该研究提供了一个全面的基准测试,用于评估蛋白质基础模型(PFM)在各种任务中的表现,并附带了一套简化评估方案。从 38 项任务和 17 个模型开始,进一步确定了 12 个核心模型和 11 个代表性任务,以实现高效且有意义的评估。该研究通过大量实验发现,当前的蛋白质基础模型研究表现出高度的同质性,并提供了深入分析以指导未来的研究方向。

蛋白质模型的 考卷 缺失
如果所有考生都参加不同的考试,有的考数学,有的考语文,你如何比较谁更优秀?实际上,蛋白质模型领域正面临类似困境。
自 2021 年 ESM-1B 模型问世以来,已有超过 17 种蛋白质模型陆续问世,涵盖纯序列模型(例如 ESM-2)、多模态模型(例如整合结构和功能的 ProTrek)。但现有基准测试要么任务太少,要么忽略多模态模型,导致评估结果支离破碎。
关键痛点:
任务不统一:模型只在定制任务上测试,无法横向比较。
多模态盲区:像ESM3这样的结构-功能融合模型,潜力巨大却缺乏系统评估。
效率低下:测试所有模型和任务耗时巨大,研究者急需 精简版 方案。
PFMBench的诞生,就是为了填上这块空白。它由西湖大学和百图生科(BioMap)团队开发,囊括了 38 个任务、17 个模型,横跨 8 大蛋白质科学领域,从结构预测到药物设计,堪称蛋白质模型的 终极考试 。
PFMBench:蛋白质模型评估的 瑞士军刀
PFMBench 的核心设计理念是模块化和高效性。它像一把多功能工具,将任务、模型和调优方法整合为统一框架,让用户轻松 插拔 组件。以下是它的三大支柱:
1、任务库:38 个任务,覆盖蛋白质全生命周期
任务分为 8 大类:注释(例如酶功能分类)、溶解度(预测蛋白能否溶解)、定位(蛋白在细胞内的位置)、突变(氨基酸替换的影响)、互作(蛋白-蛋白或蛋白-药物结合)、结构(蛋白结构预测)、生产(工业应用优化)和零样本(无需训练直接预测)。
通过严格筛选,最终选出 28 个核心任务,偏差低于 5%,确保结果可靠。例如,溶解度预测任务 DeepSol 的 AUROC 达 0.85,而突变任务 PETA_TEM 的 Spearman 相关性仅 0.14,揭示了不同任务的难度差异。
2、模型库:17 个顶尖模型,分四类竞技
纯序列模型(8个):ESM-2、ESM-C、VenusPLM、ProtGPT2、PGLM、ProtT5、ProGen2、DPLM;
序列-结构模型:SaProt、ProstT5、GearNet;
序列-功能模型:ProtST、ProLLaMA、OntoProtein;
序列-结构-功能模型:ESM3、ProTrek、ProCyon;
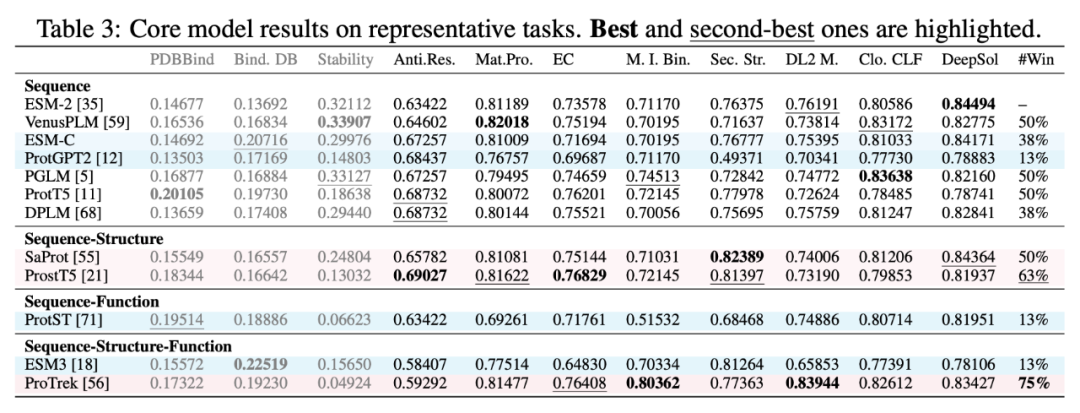
以酶分类任务(EC)为基准,筛选出 12 个核心模型,性能需达 ESM-2 的 85% 以上。其中,多模态模型 ProTrek 以 0.764 的 EC 分数领先,而纯解码器模型 ProtGPT2 表现垫底(仅0.697),凸显架构的重要性。
3、调优协议:一键切换高效训练
传统全模型训练成本高昂,PFMBench 支持参数高效微调(PEFT),例如 Adapter、LoRA 和 DoRA,仅更新少量参数即可适配新任务。实验证明,Adapter 方法在大多数任务上最优,而 DoRA 在方向-幅度分解上表现亮眼。
更聪明的是,PFMBench 提供了精简协议:只需选 11 个代表任务(例如结合亲和力 PDBBind、溶解度 DeepSol)和 2 个基线模型(ESM-2 或 ProTrek),就能快速评估新模型 省时90%,效果不打折!
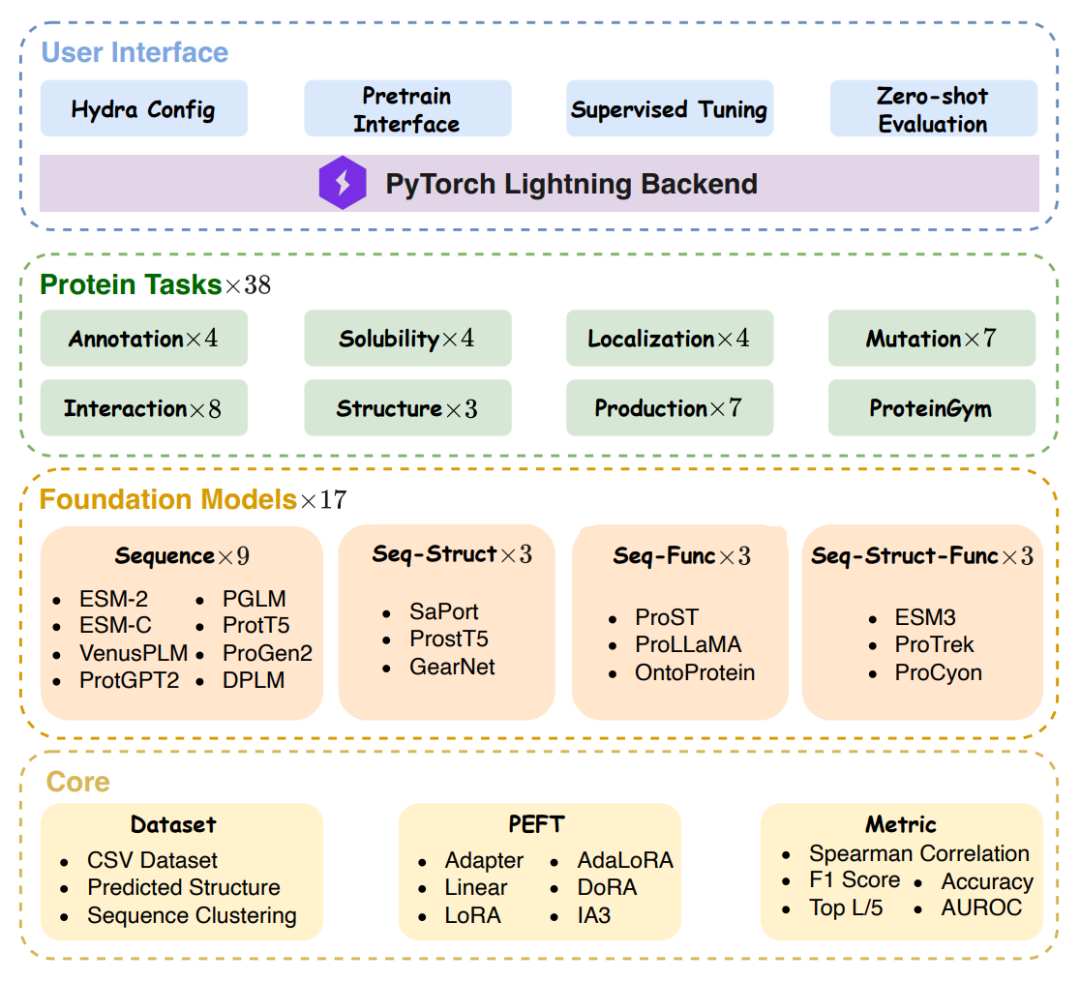
PFMBench 的总体框架
颠覆性发现:多模态模型称王,零样本测试 不靠谱
通过对数百次实验的分析,PFMBench 揭示了四大关键结论,直击行业痛点:
1、任务高度相关,11 个任务就能代表全局
通过聚类分析,38 个任务可归纳为 11 组。例如,结构预测与溶解度强相关,而突变任务自成一类。这意味着开发者只需聚焦代表任务,无需 全盘测试 。
2、多模态模型碾压纯序列模型
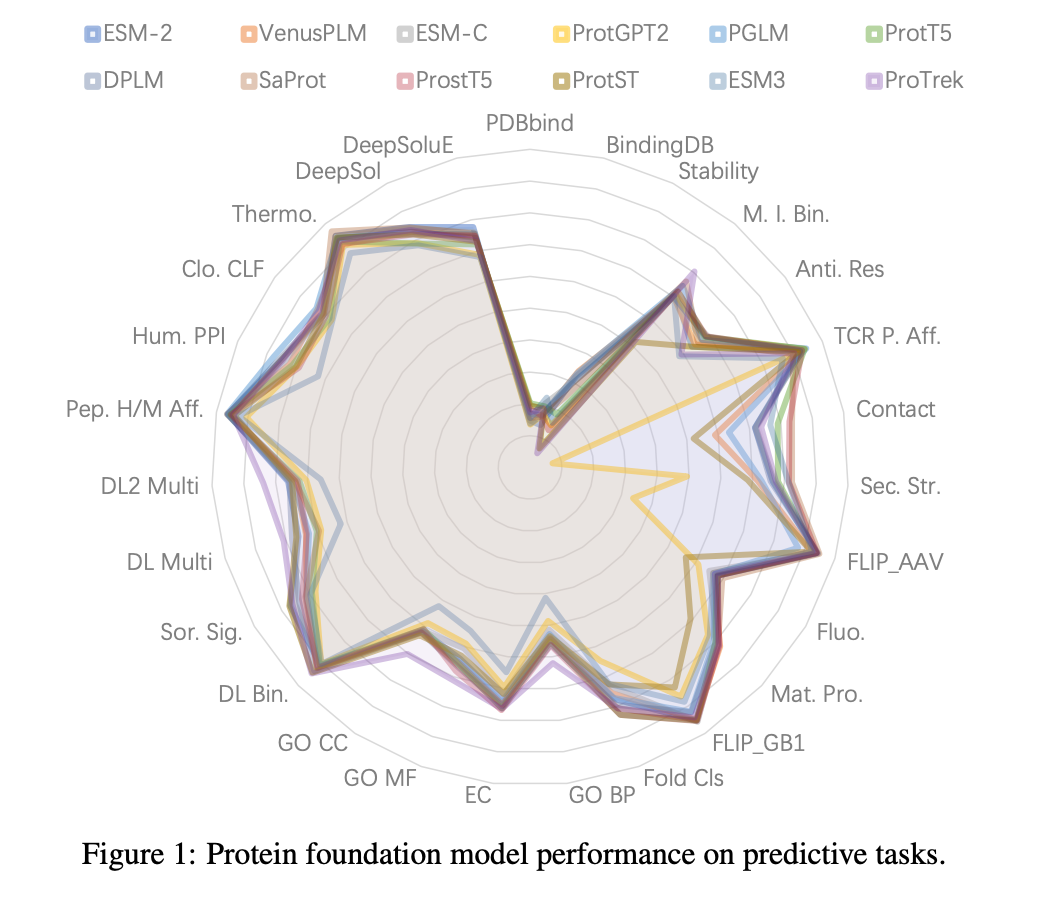
在 11 个代表任务上,ProTrek 的胜率(Win Rate)达75%,远超 ESM-2 的50%。它通过对比学习对齐序列和功能语义,在定位任务中边界清晰。反观纯序列模型,即使参数量大幅增加(例如 ESM-2 从 1.5 亿到 150 亿参数),但性能提升有限,这也提示我们,优化预训练策略比盲目扩增更有效。
3、零样本评估可能 误导 开发者
流行基准 ProteinGym(零样本突变预测)的结果与监督任务无关。例如,ESM-2 的 Spearman 为0.439,而 ProTrek 仅0.359 但这不反映真实能力。PFMBench 建议:优先监督任务,而非零样本测试。
4、模型缩放性价比低,DoRA 微调崛起
当 ESM-2 参数从 1.5 亿增至 150亿,仅 6/8 任务提升显著。而微调方法中,DoRA 通过分解权重方向与幅度,在结合任务(如BindingDB)上超越 Adapter,这提示开发者,可专注策略优化,而非硬件内卷。
12 个核心模型在 11 个代表性任务上的评估结果
为什么 PFMBench 是行业里程碑?
1、公平性终结 模型混战 :首次统一评测标准,避免模型开发者 自卖自夸 。
2、推动多模态革命:证明融合结构/功能数据的多模态模型(例如 ProTrek)是未来方向。
3、开源普惠社区:代码已在 GitHub 公开,开发者可快速复现或扩展。
4、加速生物医药应用:从抗体设计到酶优化,可靠评估缩短研发周期。
总的来说, 大语言模型 时代已经到来,蛋白质模型也已百花齐放,但唯有标准化的评测,才能让创新不走弯路。PFMBench 就像一张考卷,测出蛋白质模型的真正实力,也照亮行业的未来。
版权声明 本网站所有注明“来源:100医药网”或“来源:bioon”的文字、图片和音视频资料,版权均属于100医药网网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:100医药网”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。 87%用户都在用100医药网APP 随时阅读、评论、分享交流 请扫描二维码下载->