商业广告QQ
896000434
896000434

转录调控的核心挑战:从传统模型到泛化能力的突破
基因表达调控,是生物体内所有生命活动的根本驱动力。无论是维持正常的细胞功能,还是应对外界环境变化,这一过程都依赖于转录因子(transcription factors, TFs)与调控序列之间复杂且精密的协作。然而,研究人员对于这一关键过程的理解仍存在巨大挑战,尤其是在探索不同细胞类型的特异性基因表达模式时。
传统的转录调控模型,如Expecto、Basenji2和Enformer,虽然在特定数据集上表现良好,但它们的泛化能力较差,难以在未见过的细胞类型中准确预测基因表达。这是因为这些模型往往需要对训练数据进行针对性调优(fine-tuning),从而限制了其在全新生物学场景中的应用。此外,它们对长距离调控元件和复杂的转录因子交互网络的解析能力不足,也导致了对许多重要生物现象的认识仍不完整。例如,以往模型对远距离超过1百万碱基的顺式调控元件识别不充分,直接影响了我们对关键基因调控网络的全貌理解。
为应对这些挑战,研究团队开发了通用表达转换器(GET)模型。GET通过整合213种人类胎儿和成人细胞类型的染色质开放性数据和基因序列信息,构建了一个全面的转录调控图谱。
GET模型的诞生:一次跨越性尝试
在突破传统模型局限的努力中,通用表达转换器(General Expression Transformer, GET)应运而生。作为一种革命性的方法,GET通过解析染色质开放性数据和基因序列信息,建立了一个通用且高效的基因表达预测模型,为转录调控研究提供了全新视角。
GET的核心设计理念源于对转录调控机制的深刻理解。研究人员认识到,基因表达受到一个局部基因组区域(约2百万碱基)的调控,这些区域包含启动子和调控元件。通过分析这些区域中转录因子的结合模式及染色质的开放程度,GET能够推断出特定细胞类型的基因表达情况。模型的构建采用了嵌入和注意力机制(attention mechanism)架构,通过自监督预训练阶段,让GET学习调控序列与基因表达之间的规律。具体而言,研究人员随机屏蔽部分调控区域的数据,并训练模型预测这些区域的转录因子结合分数或染色质开放性分数,从而捕获潜在的调控语法。
在数据方面,GET利用了来自213种人类胎儿和成人细胞类型的单细胞染色质开放性测序(scATAC-seq)和RNA测序(RNA-seq)数据。这种大规模的数据整合不仅为模型提供了多样化的训练基础,还避免了对特定细胞类型的依赖。预训练阶段,GET通过伪散体(pseudobulk)数据提取通用的调控模式;微调阶段则进一步学习基因表达与调控环境之间的细节关系。
这一创新设计使GET具备了显著的泛化能力和精准性,能够在新细胞类型中实现零样本预测,同时还降低了对昂贵实验数据的依赖。
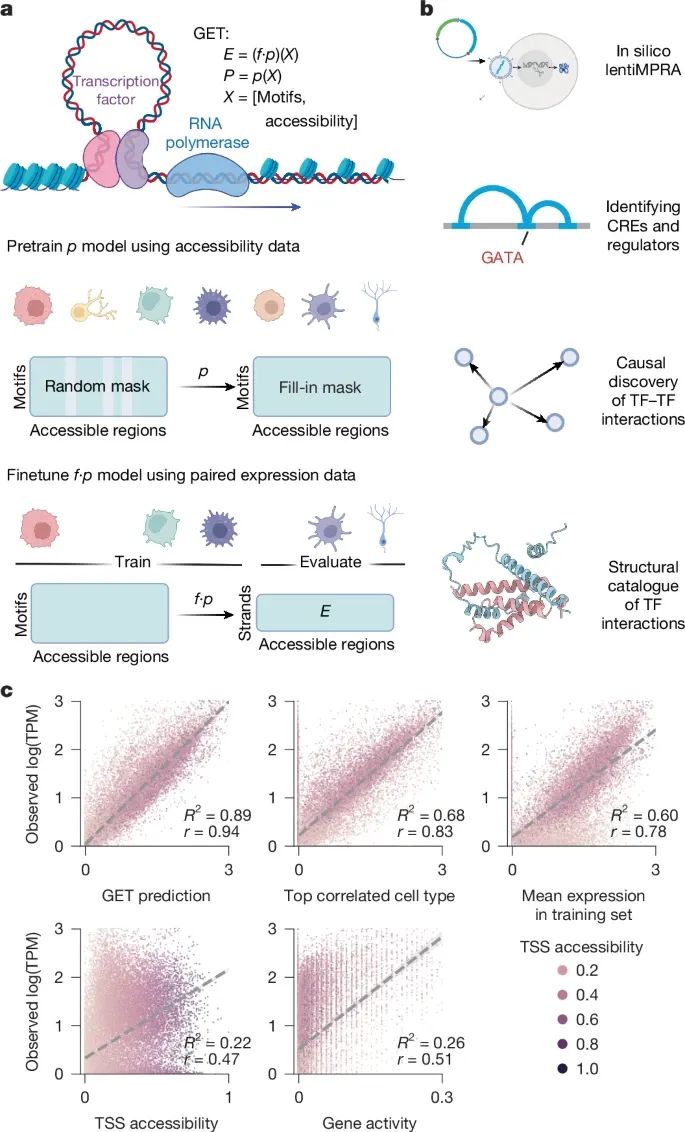
GET模型及其应用(Credit:Nature)
a. GET模型的示意图
GET模型的整体设计和核心机制。输入数据为一个 峰值(可及区域) 转录因子(TFs,基序)矩阵 ,来源于人类单细胞ATAC-seq (scATAC-seq) 数据集,覆盖了超过2百万碱基的基因组区域。这些数据总结了基因组调控序列的信息。通过在超过200种细胞类型中对输入数据进行自监督随机掩码训练,GET模型学习了转录调控的语法规则(标记为p)。接着,GET模型通过使用成对的scATAC-seq和RNA-seq数据进行微调(fine-tuning),从而学会将调控语法转换为基因表达模式,即使在未见过的细胞类型中(标记为f p)。
b. GET的下游应用
GET模型的主要应用领域。模型可以识别顺式调控元件(CRE,cis-regulatory elements)并预测基因表达水平,还能够用于构建转录调控网络。这些应用为基因调控机制的解析提供了强大的支持,并具有广泛的研究和临床价值。
c. GET在未见过细胞类型中的预测性能基准测试
以胎儿星形胶质细胞(fetal astrocytes)为例,评估了GET模型在零样本预测中的表现。图中每个点代表一个基因,颜色表示转录起始位点(TSS)附近的染色质可及性经过归一化的值。相比传统的基因活性评分(Gene Activity Score)方法,GET模型对基因表达的预测表现显著更优。此外,还与两种参考预测方法进行了对比:
Top correlated cell type:基于与胎儿星形胶质细胞基因表达最相关的训练细胞类型(如胎儿抑制性神经元)进行预测。
Mean cell type:基于所有训练细胞类型的平均基因表达进行预测。
从结果看,GET模型在胎儿星形胶质细胞中预测的基因表达与实际数据之间的相关性更高,线性拟合结果更接近理想预测。这表明,GET不仅能够从染色质开放性数据中捕捉关键的调控信息,还具有较强的泛化能力,即使在未见过的细胞类型中也能保持高精度的预测。
看见 未见的世界 :GET的预测能力
GET最大的特点之一,就是其在 未见过的世界 中的表现能力。通过算法设计和大规模数据训练,GET不仅能够在已知细胞类型中精准预测基因表达,还能以接近实验精度的水平,在从未见过的细胞类型中实现零样本预测(zero-shot prediction),这一点远超传统模型的能力范围。
在验证GET的泛化能力时,研究人员选择了星形胶质细胞(astrocytes)这一 未见过的 细胞类型。结果显示,GET预测的基因表达值与实际实验数据之间的皮尔逊相关系数达到了0.94(R = 0.88),而传统模型如基因活性评分(Gene Activity Score)的相关性仅为0.51(R = -0.67)。即使是当前最先进的模型,基于训练集细胞类型的平均表达值,预测相关性也仅能达到0.78(R = 0.53)。这充分证明了GET在跨细胞类型预测中的独特优势。
不仅如此,GET还展示了对基因表达变化趋势的敏锐捕捉能力。研究人员通过评估不同细胞类型间基因表达的对数倍数变化(log fold change),发现即使在新细胞类型中,GET依然能够准确预测这一变化,展现出强大的生物学适应性。
GET的突破性性能源于其训练策略和数据整合。通过预训练阶段,GET从大规模染色质开放性数据中提取通用调控规律;而微调阶段则进一步学习特定细胞类型中基因表达的细节模式。这种双阶段训练方法使得GET不仅能 看见 已知细胞类型,还能 理解 未见过的调控环境。
深入染色质:解锁长距离调控元件
基因表达调控的奥秘,不仅存在于启动子附近的基因区域,还隐藏在远离基因编码区域的长距离顺式调控元件(cis-regulatory elements, CREs)中。这些元件可以跨越数百万碱基,通过复杂的染色质三维结构和调控因子的相互作用,精准调控基因的表达。然而,以往的模型在识别这些长距离调控元件时表现有限。而GET模型的出现,为解开这一谜题带来了全新的工具。
在胎儿血红蛋白(fetal hemoglobin, HbF)调控的研究中,GET展示了其卓越的能力。通过对胎儿红细胞染色质开放性数据的深入解析,GET成功识别出多个关键的远程调控区域。这些区域中,尤其是位于BCL11A基因的长距离增强子区域,显著影响了HbF的表达水平。BCL11A是已知的血红蛋白表达调控因子,而GET通过模型解释技术,进一步确认了GATA转录因子在这一增强子上的重要作用。更令人意外的是,GET还发现了SOX转录因子在同一区域内的潜在参与,这为HbF调控机制增添了新维度。
相比传统模型,GET在长距离调控元件的解析上表现出色。在超过100 kb的远程基因-增强子配对预测中,GET的精准召回率(precision-recall curve, AUPRC)显著高于其他方法,如Enformer和HyenaDNA。这表明GET能够有效捕捉长距离染色质交互的复杂性,为基因表达调控的机制研究提供了更全面的视角。
转录因子网络:从分子互动到疾病预测
在转录调控的复杂网络中,转录因子(transcription factors, TFs)之间的相互作用扮演着关键角色。这些相互作用不仅影响基因表达,还可能在复杂疾病如白血病中扮演重要角色。然而,以往的研究因技术局限,难以全面解析TF之间的功能性互动。GET的出现,为揭示这些关键机制提供了新的可能。
GET利用自监督学习和因果发现算法,不仅能够准确预测转录因子在调控元件中的作用,还能够推断出潜在的TF-TF功能交互网络。在白血病的研究中,GET首次揭示了PAX5与核受体家族TF(如NR2C2)之间的相互作用。PAX5是一种B细胞特异性转录因子,与B细胞急性(B-ALL)的发病密切相关。研究发现,PAX5的G183S突变改变了其与NR2C2的相互作用强度,从而可能影响了下游基因的表达。这一发现为理解B-ALL的致病机制提供了新的线索。
GET的优势不仅体现在交互网络的发现能力,还在于其精细的结构预测能力。通过结合AlphaFold2等蛋白质结构预测工具,GET进一步揭示了TF之间的具体结合模式。例如,PAX5的八肽域与NR2C2的核受体域之间的结合,依赖于氢键和疏水作用。这些精确的分子层次洞察,使得GET在功能变异的研究中具有独特的价值。
此外,GET的预测结果不仅限于疾病机制研究,还能用于筛选潜在的治疗靶点。例如,通过GET的因果网络分析,可以识别在白血病细胞中共同调控关键基因的TF组合。这为精准药物设计和靶向干预提供了强有力的支持。
GET模型的多平台适应性:从实验室到临床
在基因组学研究中,测序平台的多样性和实验类型的复杂性往往为模型的适用性带来了巨大挑战。GET通过其强大的适应性,成功突破了这一限制,展现了在多种数据源中的广泛应用潜力。无论是实验室研究还是临床,GET都能为基因调控分析提供灵活且高效的支持。
GET模型的核心在于它对不同测序平台数据的适应能力。例如,当研究团队使用胎儿细胞类型的数据训练GET后,发现该模型能够精准预测多种成人细胞类型的基因表达,其预测相关性显著高于传统方法。此外,GET还能够跨越平台限制,应用于10 多组学测序(multiome sequencing)和数据(如胶质母细胞瘤,GBM),在不同实验数据之间展现了卓越的泛化能力。
这一适应性在实验类型的转换中同样表现优异。GET在零样本预测中,成功识别了新的顺式调控元件,并对不同平台的染色质可及性数据(如CAGE和ATAC-seq)进行了准确的调控活动推断。相比传统模型,GET的预测不仅速度更快,还具备更高的灵活性。例如,在对K562细胞系的实验中,GET仅需相同计算时间,便能够筛选出超过22万个调控元件。
这种跨平台适应性使GET在基因调控研究中的应用范围大大拓展。在临床领域,GET有望通过解析患者特定细胞类型的基因调控网络,帮助识别疾病相关的调控元件和转录因子,为疾病的早期诊断和提供新途径。
未来GET能走多远?
尽管GET已在基因调控研究中取得了显著突破,但它仍然存在一些局限性,有待进一步优化和改进。首先,GET主要依赖染色质开放性数据,这使得模型对某些关键调控因子的直接作用力分析存在不足,例如难以精确区分具有高度相似结合位点的转录因子同源物。此外,GET目前的训练基于较为粗粒度的细胞状态和区域级序列信息,尚未充分整合更精细的三维染色质结构信息或单细胞分辨率的调控特征。
在功能预测方面,GET的分辨率也受到一定限制。虽然模型可以识别长距离顺式调控元件,但其对细微的非编码变异(如单核苷酸变异)的影响预测尚需进一步提升。对于涉及多个层级生物学数据的整合能力,如结合转录因子结合位点足迹、三维基因组构象以及表观遗传修饰数据,GET还需要更深层次的优化和扩展。
未来,GET的发展潜力是无穷的。通过引入更多层次的生物数据,例如基于核苷酸水平的调控因子足迹和三维基因组数据,模型将能够更加全面地转录调控网络。此外,未来的GET版本可融入疾病状态、药物处理和基因敲除等干预数据,从而更加精准地预测调控元件和转录因子的动态行为。此外,利用生成模型技术,GET甚至可能用于设计合成调控元件和转录因子,以实现特定基因的靶向调控。
在精准医学领域,GET有望整合患者个性化基因组信息,为非编码变异的功能评估和疾病风险预测提供强大的技术支持。同时,GET的高效性和灵活性使其在新兴的多组学数据时代具有重要应用潜力,将为疾病的诊断、预防和治疗开辟更多可能性。
总之,虽然当前的GET模型还有改进空间,但它已为转录调控研究和精准医学奠定了坚实的基础。未来,通过不断完善和创新,GET必将成为生命科学研究和临床实践中不可或缺的核心工具之一。
版权声明 本网站所有注明“来源:100医药网”或“来源:bioon”的文字、图片和音视频资料,版权均属于100医药网网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:100医药网”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。 87%用户都在用100医药网APP 随时阅读、评论、分享交流 请扫描二维码下载->